Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models

Proprietary LMs such as GPT-4 are often employed to assess the quality of responses from various LMs. However, concerns including transparency, controllability, and affordability strongly motivate the development of open-source LMs specialized in evaluations. On the other hand, existing open evaluator LMs exhibit critical shortcomings: 1) they issue scores that significantly diverge from those assigned by humans, and 2) they lack the flexibility to perform both direct assessment and pairwise ranking, the two most prevalent forms of assessment. Additionally, they do not possess the ability to evaluate based on custom evaluation criteria, focusing instead on general attributes like helpfulness and harmlessness. To address these issues, we introduce Prometheus 2, a more powerful evaluator LM than its predecessor that closely mirrors human and GPT-4 judgements. Moreover, it is capable of processing both direct assessment and pair-wise ranking formats grouped with a user-defined evaluation criteria. On four direct assessment benchmarks and four pairwise ranking benchmarks, Prometheus 2 scores the highest correlation and agreement with humans and proprietary LM judges among all tested open evaluator LMs. Our models, code, and data are all publicly available at https://github.com/prometheus-eval/prometheus-eval.
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report

Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
WildChat: 1M ChatGPT Interaction Logs in the Wild

Chatbots such as GPT-4 and ChatGPT are now serving millions of users. Despite their widespread use, there remains a lack of public datasets showcasing how these tools are used by a population of users in practice. To bridge this gap, we offered free access to ChatGPT for online users in exchange for their affirmative, consensual opt-in to anonymously collect their chat transcripts and request headers. From this, we compiled WildChat, a corpus of 1 million user-ChatGPT conversations, which consists of over 2.5 million interaction turns. We compare WildChat with other popular user-chatbot interaction datasets, and find that our dataset offers the most diverse user prompts, contains the largest number of languages, and presents the richest variety of potentially toxic use-cases for researchers to study. In addition to timestamped chat transcripts, we enrich the dataset with demographic data, including state, country, and hashed IP addresses, alongside request headers. This augmentation allows for more detailed analysis of user behaviors across different geographical regions and temporal dimensions. Finally, because it captures a broad range of use cases, we demonstrate the dataset's potential utility in fine-tuning instruction-following models. WildChat is released at https://wildchat.allen.ai under AI2 ImpACT Licenses.
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation

For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge. In this paper, we propose a new way of self-attention calculation, termed Consistent Self-Attention, that significantly boosts the consistency between the generated images and augments prevalent pretrained diffusion-based text-to-image models in a zero-shot manner. To extend our method to long-range video generation, we further introduce a novel semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are significantly more stable than the modules based on latent spaces only, especially in the context of long video generation. By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents. The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from the aspect of architectural modifications. Our code is made publicly available at https://github.com/HVision-NKU/StoryDiffusion.
NeMo-Aligner: Scalable Toolkit for Efficient Model Alignment

Aligning Large Language Models (LLMs) with human values and preferences is essential for making them helpful and safe. However, building efficient tools to perform alignment can be challenging, especially for the largest and most competent LLMs which often contain tens or hundreds of billions of parameters. We create NeMo-Aligner, a toolkit for model alignment that can efficiently scale to using hundreds of GPUs for training. NeMo-Aligner comes with highly optimized and scalable implementations for major paradigms of model alignment such as: Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO), SteerLM, and Self-Play Fine-Tuning (SPIN). Additionally, our toolkit supports running most of the alignment techniques in a Parameter Efficient Fine-Tuning (PEFT) setting. NeMo-Aligner is designed for extensibility, allowing support for other alignment techniques with minimal effort. It is open-sourced with Apache 2.0 License and we invite community contributions at https://github.com/NVIDIA/NeMo-Aligner
FLAME: Factuality-Aware Alignment for Large Language Models
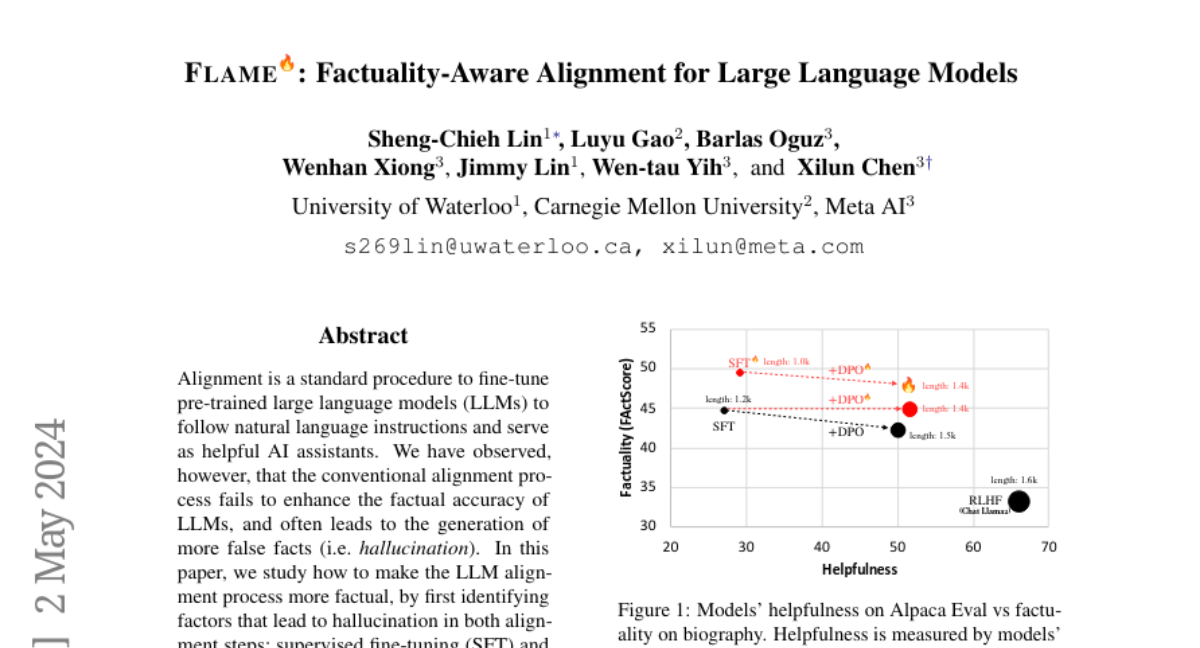
Alignment is a standard procedure to fine-tune pre-trained large language models (LLMs) to follow natural language instructions and serve as helpful AI assistants. We have observed, however, that the conventional alignment process fails to enhance the factual accuracy of LLMs, and often leads to the generation of more false facts (i.e. hallucination). In this paper, we study how to make the LLM alignment process more factual, by first identifying factors that lead to hallucination in both alignment steps:\ supervised fine-tuning (SFT) and reinforcement learning (RL). In particular, we find that training the LLM on new knowledge or unfamiliar texts can encourage hallucination. This makes SFT less factual as it trains on human labeled data that may be novel to the LLM. Furthermore, reward functions used in standard RL can also encourage hallucination, because it guides the LLM to provide more helpful responses on a diverse set of instructions, often preferring longer and more detailed responses. Based on these observations, we propose factuality-aware alignment, comprised of factuality-aware SFT and factuality-aware RL through direct preference optimization. Experiments show that our proposed factuality-aware alignment guides LLMs to output more factual responses while maintaining instruction-following capability.
Customizing Text-to-Image Models with a Single Image Pair

Art reinterpretation is the practice of creating a variation of a reference work, making a paired artwork that exhibits a distinct artistic style. We ask if such an image pair can be used to customize a generative model to capture the demonstrated stylistic difference. We propose Pair Customization, a new customization method that learns stylistic difference from a single image pair and then applies the acquired style to the generation process. Unlike existing methods that learn to mimic a single concept from a collection of images, our method captures the stylistic difference between paired images. This allows us to apply a stylistic change without overfitting to the specific image content in the examples. To address this new task, we employ a joint optimization method that explicitly separates the style and content into distinct LoRA weight spaces. We optimize these style and content weights to reproduce the style and content images while encouraging their orthogonality. During inference, we modify the diffusion process via a new style guidance based on our learned weights. Both qualitative and quantitative experiments show that our method can effectively learn style while avoiding overfitting to image content, highlighting the potential of modeling such stylistic differences from a single image pair.
LLM-AD: Large Language Model based Audio Description System

The development of Audio Description (AD) has been a pivotal step forward in making video content more accessible and inclusive. Traditionally, AD production has demanded a considerable amount of skilled labor, while existing automated approaches still necessitate extensive training to integrate multimodal inputs and tailor the output from a captioning style to an AD style. In this paper, we introduce an automated AD generation pipeline that harnesses the potent multimodal and instruction-following capacities of GPT-4V(ision). Notably, our methodology employs readily available components, eliminating the need for additional training. It produces ADs that not only comply with established natural language AD production standards but also maintain contextually consistent character information across frames, courtesy of a tracking-based character recognition module. A thorough analysis on the MAD dataset reveals that our approach achieves a performance on par with learning-based methods in automated AD production, as substantiated by a CIDEr score of 20.5.