MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training

In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, consisting of both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
Video Editing via Factorized Diffusion Distillation

We introduce Emu Video Edit (EVE), a model that establishes a new state-of-the art in video editing without relying on any supervised video editing data. To develop EVE we separately train an image editing adapter and a video generation adapter, and attach both to the same text-to-image model. Then, to align the adapters towards video editing we introduce a new unsupervised distillation procedure, Factorized Diffusion Distillation. This procedure distills knowledge from one or more teachers simultaneously, without any supervised data. We utilize this procedure to teach EVE to edit videos by jointly distilling knowledge to (i) precisely edit each individual frame from the image editing adapter, and (ii) ensure temporal consistency among the edited frames using the video generation adapter. Finally, to demonstrate the potential of our approach in unlocking other capabilities, we align additional combinations of adapters
GiT: Towards Generalist Vision Transformer through Universal Language Interface

This paper proposes a simple, yet effective framework, called GiT, simultaneously applicable for various vision tasks only with a vanilla ViT. Motivated by the universality of the Multi-layer Transformer architecture (e.g, GPT) widely used in large language models (LLMs), we seek to broaden its scope to serve as a powerful vision foundation model (VFM). However, unlike language modeling, visual tasks typically require specific modules, such as bounding box heads for detection and pixel decoders for segmentation, greatly hindering the application of powerful multi-layer transformers in the vision domain. To solve this, we design a universal language interface that empowers the successful auto-regressive decoding to adeptly unify various visual tasks, from image-level understanding (e.g., captioning), over sparse perception (e.g., detection), to dense prediction (e.g., segmentation). Based on the above designs, the entire model is composed solely of a ViT, without any specific additions, offering a remarkable architectural simplification. GiT is a multi-task visual model, jointly trained across five representative benchmarks without task-specific fine-tuning. Interestingly, our GiT builds a new benchmark in generalist performance, and fosters mutual enhancement across tasks, leading to significant improvements compared to isolated training. This reflects a similar impact observed in LLMs. Further enriching training with 27 datasets, GiT achieves strong zero-shot results over various tasks. Due to its simple design, this paradigm holds promise for narrowing the architectural gap between vision and language. Code and models will be available at \url{https://github.com/Haiyang-W/GiT}.
Veagle: Advancements in Multimodal Representation Learning

Lately, researchers in artificial intelligence have been really interested in how language and vision come together, giving rise to the development of multimodal models that aim to seamlessly integrate textual and visual information. Multimodal models, an extension of Large Language Models (LLMs), have exhibited remarkable capabilities in addressing a diverse array of tasks, ranging from image captioning and visual question answering (VQA) to visual grounding. While these models have showcased significant advancements, challenges persist in accurately interpreting images and answering the question, a common occurrence in real-world scenarios. This paper introduces a novel approach to enhance the multimodal capabilities of existing models. In response to the limitations observed in current Vision Language Models (VLMs) and Multimodal Large Language Models (MLLMs), our proposed model Veagle, incorporates a unique mechanism inspired by the successes and insights of previous works. Veagle leverages a dynamic mechanism to project encoded visual information directly into the language model. This dynamic approach allows for a more nuanced understanding of intricate details present in visual contexts. To validate the effectiveness of Veagle, we conduct comprehensive experiments on benchmark datasets, emphasizing tasks such as visual question answering and image understanding. Our results indicate a improvement of 5-6 \% in performance, with Veagle outperforming existing models by a notable margin. The outcomes underscore the model's versatility and applicability beyond traditional benchmarks.
Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding

Understanding videos is one of the fundamental directions in computer vision research, with extensive efforts dedicated to exploring various architectures such as RNN, 3D CNN, and Transformers. The newly proposed architecture of state space model, e.g., Mamba, shows promising traits to extend its success in long sequence modeling to video modeling. To assess whether Mamba can be a viable alternative to Transformers in the video understanding domain, in this work, we conduct a comprehensive set of studies, probing different roles Mamba can play in modeling videos, while investigating diverse tasks where Mamba could exhibit superiority. We categorize Mamba into four roles for modeling videos, deriving a Video Mamba Suite composed of 14 models/modules, and evaluating them on 12 video understanding tasks. Our extensive experiments reveal the strong potential of Mamba on both video-only and video-language tasks while showing promising efficiency-performance trade-offs. We hope this work could provide valuable data points and insights for future research on video understanding. Code is public: https://github.com/OpenGVLab/video-mamba-suite.
VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding

The evolution of text to visual components facilitates people's daily lives, such as generating image, videos from text and identifying the desired elements within the images. Computer vision models involving the multimodal abilities in the previous days are focused on image detection, classification based on well-defined objects. Large language models (LLMs) introduces the transformation from nature language to visual objects, which present the visual layout for text contexts. OpenAI GPT-4 has emerged as the pinnacle in LLMs, while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models and algorithms to convert 2D images to their 3D representations. However, the mismatching between the algorithms with the problem could lead to undesired results. In response to this challenge, we propose an unified VisionGPT-3D framework to consolidate the state-of-the-art vision models, thereby facilitating the development of vision-oriented AI. VisionGPT-3D provides a versatile multimodal framework building upon the strengths of multimodal foundation models. It seamlessly integrates various SOTA vision models and brings the automation in the selection of SOTA vision models, identifies the suitable 3D mesh creation algorithms corresponding to 2D depth maps analysis, generates optimal results based on diverse multimodal inputs such as text prompts. Keywords: VisionGPT-3D, 3D vision understanding, Multimodal agent
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking

When writing and talking, people sometimes pause to think. Although reasoning-focused works have often framed reasoning as a method of answering questions or completing agentic tasks, reasoning is implicit in almost all written text. For example, this applies to the steps not stated between the lines of a proof or to the theory of mind underlying a conversation. In the Self-Taught Reasoner (STaR, Zelikman et al. 2022), useful thinking is learned by inferring rationales from few-shot examples in question-answering and learning from those that lead to a correct answer. This is a highly constrained setting -- ideally, a language model could instead learn to infer unstated rationales in arbitrary text. We present Quiet-STaR, a generalization of STaR in which LMs learn to generate rationales at each token to explain future text, improving their predictions. We address key challenges, including 1) the computational cost of generating continuations, 2) the fact that the LM does not initially know how to generate or use internal thoughts, and 3) the need to predict beyond individual next tokens. To resolve these, we propose a tokenwise parallel sampling algorithm, using learnable tokens indicating a thought's start and end, and an extended teacher-forcing technique. Encouragingly, generated rationales disproportionately help model difficult-to-predict tokens and improve the LM's ability to directly answer difficult questions. In particular, after continued pretraining of an LM on a corpus of internet text with Quiet-STaR, we find zero-shot improvements on GSM8K (5.9%$\rightarrow$10.9%) and CommonsenseQA (36.3%$\rightarrow$47.2%) and observe a perplexity improvement of difficult tokens in natural text. Crucially, these improvements require no fine-tuning on these tasks. Quiet-STaR marks a step towards LMs that can learn to reason in a more general and scalable way.
BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences

Effective attention modules have played a crucial role in the success of Transformer-based large language models (LLMs), but the quadratic time and memory complexities of these attention modules also pose a challenge when processing long sequences. One potential solution for the long sequence problem is to utilize distributed clusters to parallelize the computation of attention modules across multiple devices (e.g., GPUs). However, adopting a distributed approach inevitably introduces extra memory overheads to store local attention results and incurs additional communication costs to aggregate local results into global ones. In this paper, we propose a distributed attention framework named ``BurstAttention'' to optimize memory access and communication operations at both the global cluster and local device levels. In our experiments, we compare BurstAttention with other competitive distributed attention solutions for long sequence processing. The experimental results under different length settings demonstrate that BurstAttention offers significant advantages for processing long sequences compared with these competitive baselines, reducing 40% communication overheads and achieving 2 X speedup during training 32K sequence length on 8 X A100.
Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring

Large Vision Language Models have achieved fine-grained object perception, but the limitation of image resolution remains a significant obstacle to surpass the performance of task-specific experts in complex and dense scenarios. Such limitation further restricts the model's potential to achieve nuanced visual and language referring in domains such as GUI Agents, Counting and \etc. To address this issue, we introduce a unified high-resolution generalist model, Griffon v2, enabling flexible object referring with visual and textual prompts. To efficiently scaling up image resolution, we design a simple and lightweight down-sampling projector to overcome the input tokens constraint in Large Language Models. This design inherently preserves the complete contexts and fine details, and significantly improves multimodal perception ability especially for small objects. Building upon this, we further equip the model with visual-language co-referring capabilities through a plug-and-play visual tokenizer. It enables user-friendly interaction with flexible target images, free-form texts and even coordinates. Experiments demonstrate that Griffon v2 can localize any objects of interest with visual and textual referring, achieve state-of-the-art performance on REC, phrase grounding, and REG tasks, and outperform expert models in object detection and object counting. Data, codes and models will be released at https://github.com/jefferyZhan/Griffon.
LocalMamba: Visual State Space Model with Windowed Selective Scan

Recent advancements in state space models, notably Mamba, have demonstrated significant progress in modeling long sequences for tasks like language understanding. Yet, their application in vision tasks has not markedly surpassed the performance of traditional Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). This paper posits that the key to enhancing Vision Mamba (ViM) lies in optimizing scan directions for sequence modeling. Traditional ViM approaches, which flatten spatial tokens, overlook the preservation of local 2D dependencies, thereby elongating the distance between adjacent tokens. We introduce a novel local scanning strategy that divides images into distinct windows, effectively capturing local dependencies while maintaining a global perspective. Additionally, acknowledging the varying preferences for scan patterns across different network layers, we propose a dynamic method to independently search for the optimal scan choices for each layer, substantially improving performance. Extensive experiments across both plain and hierarchical models underscore our approach's superiority in effectively capturing image representations. For example, our model significantly outperforms Vim-Ti by 3.1% on ImageNet with the same 1.5G FLOPs. Code is available at: https://github.com/hunto/LocalMamba.
Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset

Using vision-language models (VLMs) in web development presents a promising strategy to increase efficiency and unblock no-code solutions: by providing a screenshot or a sketch of a UI, a VLM could generate the code to reproduce it, for instance in a language like HTML. Despite the advancements in VLMs for various tasks, the specific challenge of converting a screenshot into a corresponding HTML has been minimally explored. We posit that this is mainly due to the absence of a suitable, high-quality dataset. This work introduces WebSight, a synthetic dataset consisting of 2 million pairs of HTML codes and their corresponding screenshots. We fine-tune a foundational VLM on our dataset and show proficiency in converting webpage screenshots to functional HTML code. To accelerate the research in this area, we open-source WebSight.
Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
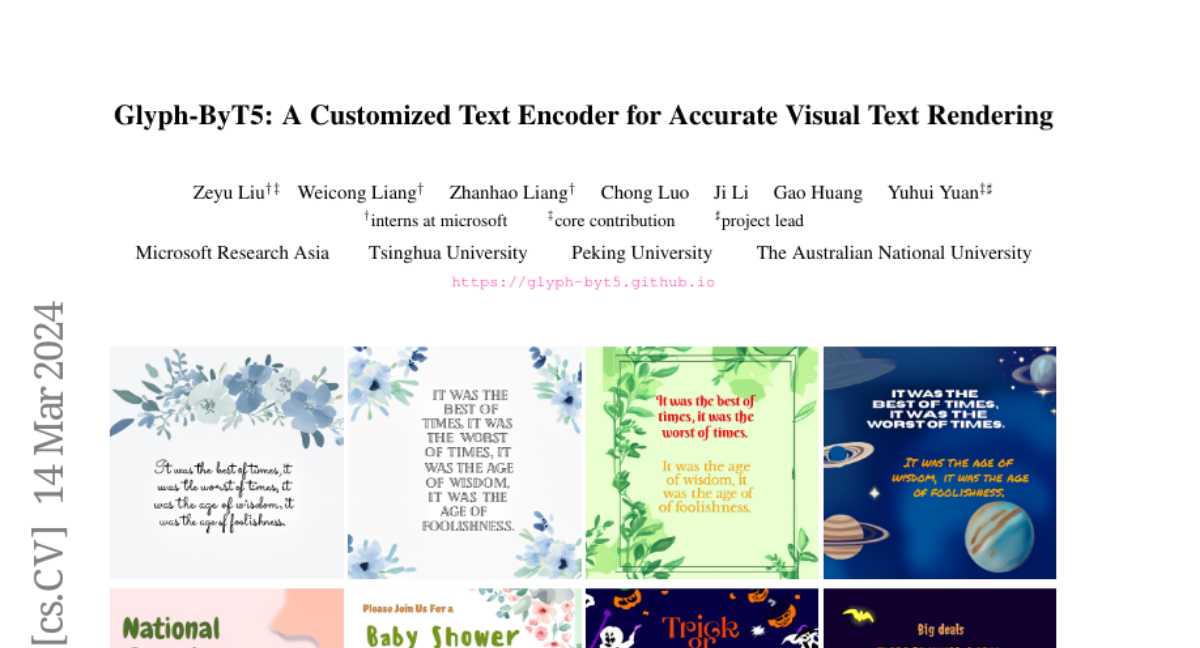
Visual text rendering poses a fundamental challenge for contemporary text-to-image generation models, with the core problem lying in text encoder deficiencies. To achieve accurate text rendering, we identify two crucial requirements for text encoders: character awareness and alignment with glyphs. Our solution involves crafting a series of customized text encoder, Glyph-ByT5, by fine-tuning the character-aware ByT5 encoder using a meticulously curated paired glyph-text dataset. We present an effective method for integrating Glyph-ByT5 with SDXL, resulting in the creation of the Glyph-SDXL model for design image generation. This significantly enhances text rendering accuracy, improving it from less than $20\%$ to nearly $90\%$ on our design image benchmark. Noteworthy is Glyph-SDXL's newfound ability for text paragraph rendering, achieving high spelling accuracy for tens to hundreds of characters with automated multi-line layouts. Finally, through fine-tuning Glyph-SDXL with a small set of high-quality, photorealistic images featuring visual text, we showcase a substantial improvement in scene text rendering capabilities in open-domain real images. These compelling outcomes aim to encourage further exploration in designing customized text encoders for diverse and challenging tasks.
StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control

The enormous success of diffusion models in text-to-image synthesis has made them promising candidates for the next generation of end-user applications for image generation and editing. Previous works have focused on improving the usability of diffusion models by reducing the inference time or increasing user interactivity by allowing new, fine-grained controls such as region-based text prompts. However, we empirically find that integrating both branches of works is nontrivial, limiting the potential of diffusion models. To solve this incompatibility, we present StreamMultiDiffusion, the first real-time region-based text-to-image generation framework. By stabilizing fast inference techniques and restructuring the model into a newly proposed multi-prompt stream batch architecture, we achieve $\times 10$ faster panorama generation than existing solutions, and the generation speed of 1.57 FPS in region-based text-to-image synthesis on a single RTX 2080 Ti GPU. Our solution opens up a new paradigm for interactive image generation named semantic palette, where high-quality images are generated in real-time from given multiple hand-drawn regions, encoding prescribed semantic meanings (e.g., eagle, girl). Our code and demo application are available at https://github.com/ironjr/StreamMultiDiffusion.
3D-VLA: A 3D Vision-Language-Action Generative World Model

Recent vision-language-action (VLA) models rely on 2D inputs, lacking integration with the broader realm of the 3D physical world. Furthermore, they perform action prediction by learning a direct mapping from perception to action, neglecting the vast dynamics of the world and the relations between actions and dynamics. In contrast, human beings are endowed with world models that depict imagination about future scenarios to plan actions accordingly. To this end, we propose 3D-VLA by introducing a new family of embodied foundation models that seamlessly link 3D perception, reasoning, and action through a generative world model. Specifically, 3D-VLA is built on top of a 3D-based large language model (LLM), and a set of interaction tokens is introduced to engage with the embodied environment. Furthermore, to inject generation abilities into the model, we train a series of embodied diffusion models and align them into the LLM for predicting the goal images and point clouds. To train our 3D-VLA, we curate a large-scale 3D embodied instruction dataset by extracting vast 3D-related information from existing robotics datasets. Our experiments on held-in datasets demonstrate that 3D-VLA significantly improves the reasoning, multimodal generation, and planning capabilities in embodied environments, showcasing its potential in real-world applications.