Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
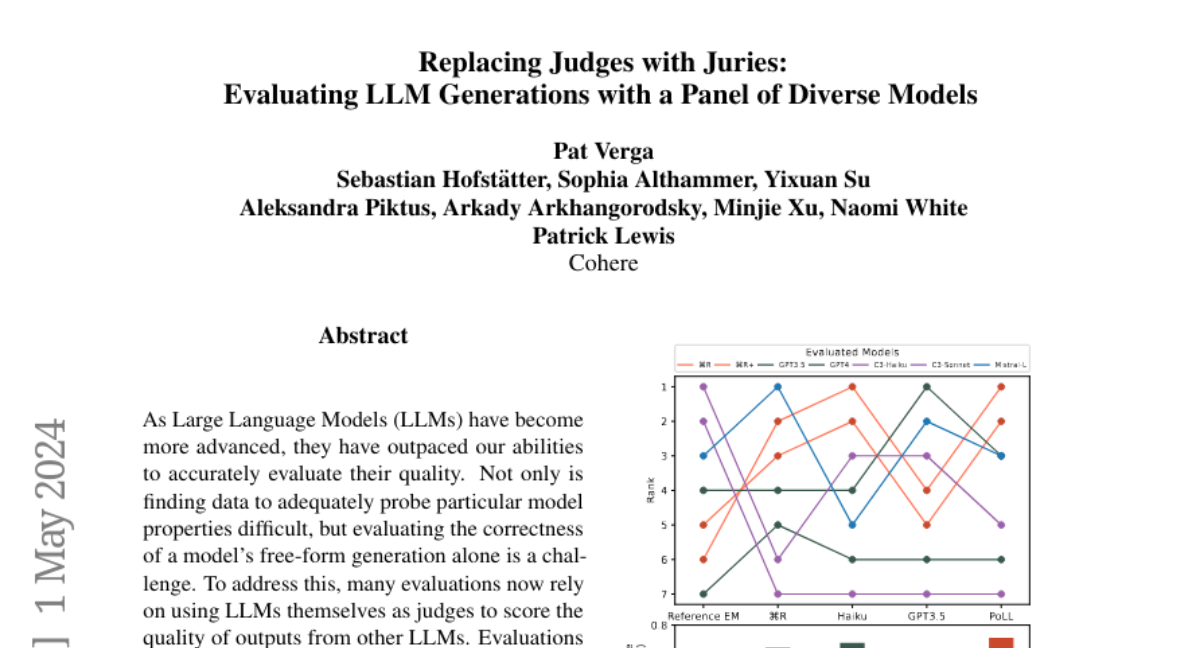
As Large Language Models (LLMs) have become more advanced, they have outpaced our abilities to accurately evaluate their quality. Not only is finding data to adequately probe particular model properties difficult, but evaluating the correctness of a model's freeform generation alone is a challenge. To address this, many evaluations now rely on using LLMs themselves as judges to score the quality of outputs from other LLMs. Evaluations most commonly use a single large model like GPT4. While this method has grown in popularity, it is costly, has been shown to introduce intramodel bias, and in this work, we find that very large models are often unnecessary. We propose instead to evaluate models using a Panel of LLm evaluators (PoLL). Across three distinct judge settings and spanning six different datasets, we find that using a PoLL composed of a larger number of smaller models outperforms a single large judge, exhibits less intra-model bias due to its composition of disjoint model families, and does so while being over seven times less expensive.
LEGENT: Open Platform for Embodied Agents

Despite advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), their integration into language-grounded, human-like embodied agents remains incomplete, hindering complex real-life task performance in physical environments. Existing integrations often feature limited open sourcing, challenging collective progress in this field. We introduce LEGENT, an open, scalable platform for developing embodied agents using LLMs and LMMs. LEGENT offers a dual approach: a rich, interactive 3D environment with communicable and actionable agents, paired with a user-friendly interface, and a sophisticated data generation pipeline utilizing advanced algorithms to exploit supervision from simulated worlds at scale. In our experiments, an embryonic vision-language-action model trained on LEGENT-generated data surpasses GPT-4V in embodied tasks, showcasing promising generalization capabilities.
Kangaroo: Lossless Self-Speculative Decoding via Double Early Exiting

Speculative decoding has demonstrated its effectiveness in accelerating the inference of large language models while maintaining a consistent sampling distribution. However, the conventional approach of training a separate draft model to achieve a satisfactory token acceptance rate can be costly. Drawing inspiration from early exiting, we propose a novel self-speculative decoding framework \emph{Kangaroo}, which uses a fixed shallow sub-network as a self-draft model, with the remaining layers serving as the larger target model. We train a lightweight and efficient adapter module on top of the sub-network to bridge the gap between the sub-network and the full model's representation ability. It is noteworthy that the inference latency of the self-draft model may no longer be negligible compared to the large model, necessitating strategies to increase the token acceptance rate while minimizing the drafting steps of the small model. To address this challenge, we introduce an additional early exiting mechanism for generating draft tokens. Specifically, we halt the small model's subsequent prediction during the drafting phase once the confidence level for the current token falls below a certain threshold. Extensive experiments on the Spec-Bench demonstrate the effectiveness of Kangaroo. Under single-sequence verification, Kangaroo achieves speedups up to $1.68\times$ on Spec-Bench, outperforming Medusa-1 with 88.7\% fewer additional parameters (67M compared to 591M). The code for Kangaroo is available at https://github.com/Equationliu/Kangaroo.
Ag2Manip: Learning Novel Manipulation Skills with Agent-Agnostic Visual and Action Representations

Autonomous robotic systems capable of learning novel manipulation tasks are poised to transform industries from manufacturing to service automation. However, modern methods (e.g., VIP and R3M) still face significant hurdles, notably the domain gap among robotic embodiments and the sparsity of successful task executions within specific action spaces, resulting in misaligned and ambiguous task representations. We introduce Ag2Manip (Agent-Agnostic representations for Manipulation), a framework aimed at surmounting these challenges through two key innovations: a novel agent-agnostic visual representation derived from human manipulation videos, with the specifics of embodiments obscured to enhance generalizability; and an agent-agnostic action representation abstracting a robot's kinematics to a universal agent proxy, emphasizing crucial interactions between end-effector and object. Ag2Manip's empirical validation across simulated benchmarks like FrankaKitchen, ManiSkill, and PartManip shows a 325% increase in performance, achieved without domain-specific demonstrations. Ablation studies underline the essential contributions of the visual and action representations to this success. Extending our evaluations to the real world, Ag2Manip significantly improves imitation learning success rates from 50% to 77.5%, demonstrating its effectiveness and generalizability across both simulated and physical environments.
Capabilities of Gemini Models in Medicine

Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
BlenderAlchemy: Editing 3D Graphics with Vision-Language Models

Graphics design is important for various applications, including movie production and game design. To create a high-quality scene, designers usually need to spend hours in software like Blender, in which they might need to interleave and repeat operations, such as connecting material nodes, hundreds of times. Moreover, slightly different design goals may require completely different sequences, making automation difficult. In this paper, we propose a system that leverages Vision-Language Models (VLMs), like GPT-4V, to intelligently search the design action space to arrive at an answer that can satisfy a user's intent. Specifically, we design a vision-based edit generator and state evaluator to work together to find the correct sequence of actions to achieve the goal. Inspired by the role of visual imagination in the human design process, we supplement the visual reasoning capabilities of VLMs with "imagined" reference images from image-generation models, providing visual grounding of abstract language descriptions. In this paper, we provide empirical evidence suggesting our system can produce simple but tedious Blender editing sequences for tasks such as editing procedural materials from text and/or reference images, as well as adjusting lighting configurations for product renderings in complex scenes.
DressCode: Autoregressively Sewing and Generating Garments from Text Guidance

Apparel's significant role in human appearance underscores the importance of garment digitalization for digital human creation. Recent advances in 3D content creation are pivotal for digital human creation. Nonetheless, garment generation from text guidance is still nascent. We introduce a text-driven 3D garment generation framework, DressCode, which aims to democratize design for novices and offer immense potential in fashion design, virtual try-on, and digital human creation. For our framework, we first introduce SewingGPT, a GPT-based architecture integrating cross-attention with text-conditioned embedding to generate sewing patterns with text guidance. We also tailored a pre-trained Stable Diffusion for high-quality, tile-based PBR texture generation. By leveraging a large language model, our framework generates CG-friendly garments through natural language interaction. Our method also facilitates pattern completion and texture editing, streamlining the design process through user-friendly interaction. This framework fosters innovation by allowing creators to freely experiment with designs and incorporate unique elements into their work, thereby igniting new ideas and artistic possibilities. With comprehensive evaluations and comparisons with other state-of-the-art methods, our method showcases the best quality and alignment with input prompts. User studies further validate our high-quality rendering results, highlighting its practical utility and potential in production settings. Our project page is https://IHe-KaiI.github.io/DressCode/.