Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention

This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
RULER: What's the Real Context Size of Your Long-Context Language Models?

The needle-in-a-haystack (NIAH) test, which examines the ability to retrieve a piece of information (the "needle") from long distractor texts (the "haystack"), has been widely adopted to evaluate long-context language models (LMs). However, this simple retrieval-based test is indicative of only a superficial form of long-context understanding. To provide a more comprehensive evaluation of long-context LMs, we create a new synthetic benchmark RULER with flexible configurations for customized sequence length and task complexity. RULER expands upon the vanilla NIAH test to encompass variations with diverse types and quantities of needles. Moreover, RULER introduces new task categories multi-hop tracing and aggregation to test behaviors beyond searching from context. We evaluate ten long-context LMs with 13 representative tasks in RULER. Despite achieving nearly perfect accuracy in the vanilla NIAH test, all models exhibit large performance drops as the context length increases. While these models all claim context sizes of 32K tokens or greater, only four models (GPT-4, Command-R, Yi-34B, and Mixtral) can maintain satisfactory performance at the length of 32K. Our analysis of Yi-34B, which supports context length of 200K, reveals large room for improvement as we increase input length and task complexity. We open source RULER to spur comprehensive evaluation of long-context LMs.
RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion
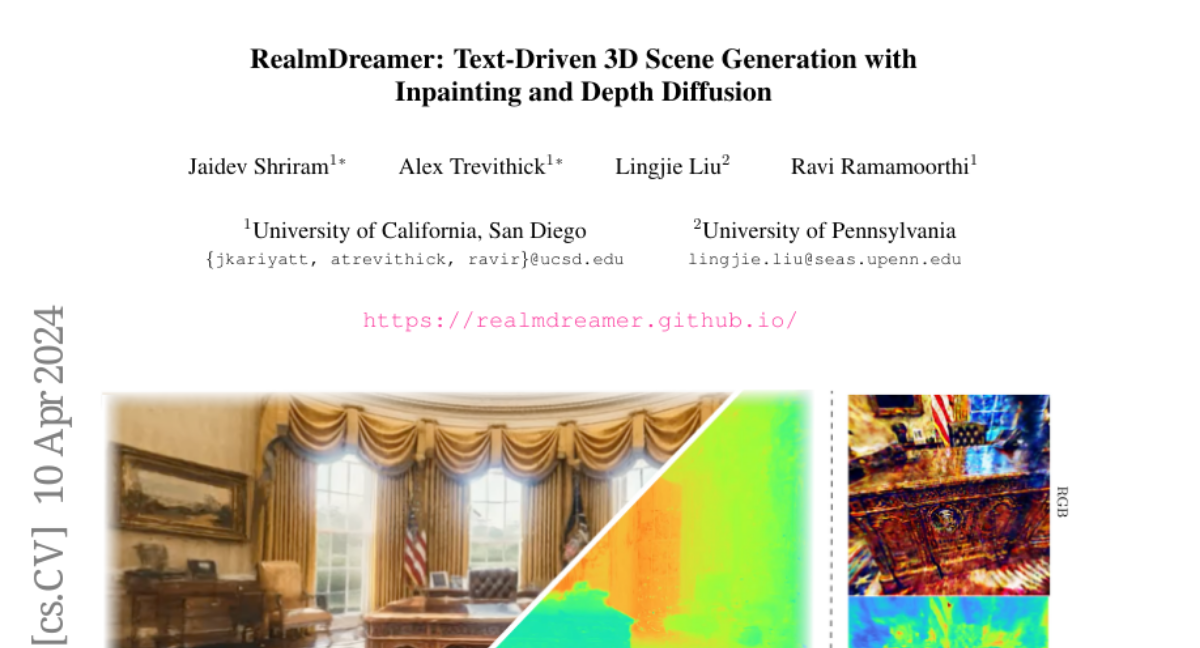
We introduce RealmDreamer, a technique for generation of general forward-facing 3D scenes from text descriptions. Our technique optimizes a 3D Gaussian Splatting representation to match complex text prompts. We initialize these splats by utilizing the state-of-the-art text-to-image generators, lifting their samples into 3D, and computing the occlusion volume. We then optimize this representation across multiple views as a 3D inpainting task with image-conditional diffusion models. To learn correct geometric structure, we incorporate a depth diffusion model by conditioning on the samples from the inpainting model, giving rich geometric structure. Finally, we finetune the model using sharpened samples from image generators. Notably, our technique does not require video or multi-view data and can synthesize a variety of high-quality 3D scenes in different styles, consisting of multiple objects. Its generality additionally allows 3D synthesis from a single image.
Urban Architect: Steerable 3D Urban Scene Generation with Layout Prior

Text-to-3D generation has achieved remarkable success via large-scale text-to-image diffusion models. Nevertheless, there is no paradigm for scaling up the methodology to urban scale. Urban scenes, characterized by numerous elements, intricate arrangement relationships, and vast scale, present a formidable barrier to the interpretability of ambiguous textual descriptions for effective model optimization. In this work, we surmount the limitations by introducing a compositional 3D layout representation into text-to-3D paradigm, serving as an additional prior. It comprises a set of semantic primitives with simple geometric structures and explicit arrangement relationships, complementing textual descriptions and enabling steerable generation. Upon this, we propose two modifications -- (1) We introduce Layout-Guided Variational Score Distillation to address model optimization inadequacies. It conditions the score distillation sampling process with geometric and semantic constraints of 3D layouts. (2) To handle the unbounded nature of urban scenes, we represent 3D scene with a Scalable Hash Grid structure, incrementally adapting to the growing scale of urban scenes. Extensive experiments substantiate the capability of our framework to scale text-to-3D generation to large-scale urban scenes that cover over 1000m driving distance for the first time. We also present various scene editing demonstrations, showing the powers of steerable urban scene generation. Website: https://urbanarchitect.github.io.
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting

The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{\circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{\circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary "flat" (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{\circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
BRAVE: Broadening the visual encoding of vision-language models

Vision-language models (VLMs) are typically composed of a vision encoder, e.g. CLIP, and a language model (LM) that interprets the encoded features to solve downstream tasks. Despite remarkable progress, VLMs are subject to several shortcomings due to the limited capabilities of vision encoders, e.g. "blindness" to certain image features, visual hallucination, etc. To address these issues, we study broadening the visual encoding capabilities of VLMs. We first comprehensively benchmark several vision encoders with different inductive biases for solving VLM tasks. We observe that there is no single encoding configuration that consistently achieves top performance across different tasks, and encoders with different biases can perform surprisingly similarly. Motivated by this, we introduce a method, named BRAVE, that consolidates features from multiple frozen encoders into a more versatile representation that can be directly fed as the input to a frozen LM. BRAVE achieves state-of-the-art performance on a broad range of captioning and VQA benchmarks and significantly reduces the aforementioned issues of VLMs, while requiring a smaller number of trainable parameters than existing methods and having a more compressed representation. Our results highlight the potential of incorporating different visual biases for a more broad and contextualized visual understanding of VLMs.
Adapting LLaMA Decoder to Vision Transformer

This work examines whether decoder-only Transformers such as LLaMA, which were originally designed for large language models (LLMs), can be adapted to the computer vision field. We first "LLaMAfy" a standard ViT step-by-step to align with LLaMA's architecture, and find that directly applying a casual mask to the self-attention brings an attention collapse issue, resulting in the failure to the network training. We suggest to reposition the class token behind the image tokens with a post-sequence class token technique to overcome this challenge, enabling causal self-attention to efficiently capture the entire image's information. Additionally, we develop a soft mask strategy that gradually introduces a casual mask to the self-attention at the onset of training to facilitate the optimization behavior. The tailored model, dubbed as image LLaMA (iLLaMA), is akin to LLaMA in architecture and enables direct supervised learning. Its causal self-attention boosts computational efficiency and learns complex representation by elevating attention map ranks. iLLaMA rivals the performance with its encoder-only counterparts, achieving 75.1% ImageNet top-1 accuracy with only 5.7M parameters. Scaling the model to ~310M and pre-training on ImageNet-21K further enhances the accuracy to 86.0%. Extensive experiments demonstrate iLLaMA's reliable properties: calibration, shape-texture bias, quantization compatibility, ADE20K segmentation and CIFAR transfer learning. We hope our study can kindle fresh views to visual model design in the wave of LLMs. Pre-trained models and codes are available here.