Rho-1: Not All Tokens Are What You Need

Previous language model pre-training methods have uniformly applied a next-token prediction loss to all training tokens. Challenging this norm, we posit that "Not all tokens in a corpus are equally important for language model training". Our initial analysis delves into token-level training dynamics of language model, revealing distinct loss patterns for different tokens. Leveraging these insights, we introduce a new language model called Rho-1. Unlike traditional LMs that learn to predict every next token in a corpus, Rho-1 employs Selective Language Modeling (SLM), which selectively trains on useful tokens that aligned with the desired distribution. This approach involves scoring pretraining tokens using a reference model, and then training the language model with a focused loss on tokens with higher excess loss. When continual pretraining on 15B OpenWebMath corpus, Rho-1 yields an absolute improvement in few-shot accuracy of up to 30% in 9 math tasks. After fine-tuning, Rho-1-1B and 7B achieved state-of-the-art results of 40.6% and 51.8% on MATH dataset, respectively - matching DeepSeekMath with only 3% of the pretraining tokens. Furthermore, when pretraining on 80B general tokens, Rho-1 achieves 6.8% average enhancement across 15 diverse tasks, increasing both efficiency and performance of the language model pre-training.
ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback

To enhance the controllability of text-to-image diffusion models, existing efforts like ControlNet incorporated image-based conditional controls. In this paper, we reveal that existing methods still face significant challenges in generating images that align with the image conditional controls. To this end, we propose ControlNet++, a novel approach that improves controllable generation by explicitly optimizing pixel-level cycle consistency between generated images and conditional controls. Specifically, for an input conditional control, we use a pre-trained discriminative reward model to extract the corresponding condition of the generated images, and then optimize the consistency loss between the input conditional control and extracted condition. A straightforward implementation would be generating images from random noises and then calculating the consistency loss, but such an approach requires storing gradients for multiple sampling timesteps, leading to considerable time and memory costs. To address this, we introduce an efficient reward strategy that deliberately disturbs the input images by adding noise, and then uses the single-step denoised images for reward fine-tuning. This avoids the extensive costs associated with image sampling, allowing for more efficient reward fine-tuning. Extensive experiments show that ControlNet++ significantly improves controllability under various conditional controls. For example, it achieves improvements over ControlNet by 7.9% mIoU, 13.4% SSIM, and 7.6% RMSE, respectively, for segmentation mask, line-art edge, and depth conditions.
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments

Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWorld, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWorld can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWorld, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWorld reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using OSWorld provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks. Our code, environment, baseline models, and data are publicly available at https://os-world.github.io.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models

We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
WILBUR: Adaptive In-Context Learning for Robust and Accurate Web Agents

In the realm of web agent research, achieving both generalization and accuracy remains a challenging problem. Due to high variance in website structure, existing approaches often fail. Moreover, existing fine-tuning and in-context learning techniques fail to generalize across multiple websites. We introduce Wilbur, an approach that uses a differentiable ranking model and a novel instruction synthesis technique to optimally populate a black-box large language model's prompt with task demonstrations from previous runs. To maximize end-to-end success rates, we also propose an intelligent backtracking mechanism that learns and recovers from its mistakes. Finally, we show that our ranking model can be trained on data from a generative auto-curriculum which samples representative goals from an LLM, runs the agent, and automatically evaluates it, with no manual annotation. Wilbur achieves state-of-the-art results on the WebVoyager benchmark, beating text-only models by 8% overall, and up to 36% on certain websites. On the same benchmark, Wilbur is within 5% of a strong multi-modal model despite only receiving textual inputs, and further analysis reveals a substantial number of failures are due to engineering challenges of operating the web.
Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models

While Ferret seamlessly integrates regional understanding into the Large Language Model (LLM) to facilitate its referring and grounding capability, it poses certain limitations: constrained by the pre-trained fixed visual encoder and failed to perform well on broader tasks. In this work, we unveil Ferret-v2, a significant upgrade to Ferret, with three key designs. (1) Any resolution grounding and referring: A flexible approach that effortlessly handles higher image resolution, improving the model's ability to process and understand images in greater detail. (2) Multi-granularity visual encoding: By integrating the additional DINOv2 encoder, the model learns better and diverse underlying contexts for global and fine-grained visual information. (3) A three-stage training paradigm: Besides image-caption alignment, an additional stage is proposed for high-resolution dense alignment before the final instruction tuning. Experiments show that Ferret-v2 provides substantial improvements over Ferret and other state-of-the-art methods, thanks to its high-resolution scaling and fine-grained visual processing.
JetMoE: Reaching Llama2 Performance with 0.1M Dollars

Large Language Models (LLMs) have achieved remarkable results, but their increasing resource demand has become a major obstacle to the development of powerful and accessible super-human intelligence. This report introduces JetMoE-8B, a new LLM trained with less than $0.1 million, using 1.25T tokens from carefully mixed open-source corpora and 30,000 H100 GPU hours. Despite its low cost, the JetMoE-8B demonstrates impressive performance, with JetMoE-8B outperforming the Llama2-7B model and JetMoE-8B-Chat surpassing the Llama2-13B-Chat model. These results suggest that LLM training can be much more cost-effective than generally thought. JetMoE-8B is based on an efficient Sparsely-gated Mixture-of-Experts (SMoE) architecture, composed of attention and feedforward experts. Both layers are sparsely activated, allowing JetMoE-8B to have 8B parameters while only activating 2B for each input token, reducing inference computation by about 70% compared to Llama2-7B. Moreover, JetMoE-8B is highly open and academia-friendly, using only public datasets and training code. All training parameters and data mixtures have been detailed in this report to facilitate future efforts in the development of open foundation models. This transparency aims to encourage collaboration and further advancements in the field of accessible and efficient LLMs. The model weights are publicly available at https://github.com/myshell-ai/JetMoE.
Best Practices and Lessons Learned on Synthetic Data for Language Models

The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
HGRN2: Gated Linear RNNs with State Expansion

Hierarchically gated linear RNN (HGRN,Qin et al. 2023) has demonstrated competitive training speed and performance in language modeling, while offering efficient inference. However, the recurrent state size of HGRN remains relatively small, which limits its expressiveness.To address this issue, inspired by linear attention, we introduce a simple outer-product-based state expansion mechanism so that the recurrent state size can be significantly enlarged without introducing any additional parameters. The linear attention form also allows for hardware-efficient training.Our extensive experiments verify the advantage of HGRN2 over HGRN1 in language modeling, image classification, and Long Range Arena.Our largest 3B HGRN2 model slightly outperforms Mamba and LLaMa Architecture Transformer for language modeling in a controlled experiment setting; and performs competitively with many open-source 3B models in downstream evaluation while using much fewer total training tokens.
From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples

We analyze how well pre-trained large language models (e.g., Llama2, GPT-4, Claude 3, etc) can do linear and non-linear regression when given in-context examples, without any additional training or gradient updates. Our findings reveal that several large language models (e.g., GPT-4, Claude 3) are able to perform regression tasks with a performance rivaling (or even outperforming) that of traditional supervised methods such as Random Forest, Bagging, or Gradient Boosting. For example, on the challenging Friedman #2 regression dataset, Claude 3 outperforms many supervised methods such as AdaBoost, SVM, Random Forest, KNN, or Gradient Boosting. We then investigate how well the performance of large language models scales with the number of in-context exemplars. We borrow from the notion of regret from online learning and empirically show that LLMs are capable of obtaining a sub-linear regret.
Audio Dialogues: Dialogues dataset for audio and music understanding

Existing datasets for audio understanding primarily focus on single-turn interactions (i.e. audio captioning, audio question answering) for describing audio in natural language, thus limiting understanding audio via interactive dialogue. To address this gap, we introduce Audio Dialogues: a multi-turn dialogue dataset containing 163.8k samples for general audio sounds and music. In addition to dialogues, Audio Dialogues also has question-answer pairs to understand and compare multiple input audios together. Audio Dialogues leverages a prompting-based approach and caption annotations from existing datasets to generate multi-turn dialogues using a Large Language Model (LLM). We evaluate existing audio-augmented large language models on our proposed dataset to demonstrate the complexity and applicability of Audio Dialogues. Our code for generating the dataset will be made publicly available. Detailed prompts and generated dialogues can be found on the demo website https://audiodialogues.github.io/.
LLoCO: Learning Long Contexts Offline

Processing long contexts remains a challenge for large language models (LLMs) due to the quadratic computational and memory overhead of the self-attention mechanism and the substantial KV cache sizes during generation. We propose a novel approach to address this problem by learning contexts offline through context compression and in-domain parameter-efficient finetuning. Our method enables an LLM to create a concise representation of the original context and efficiently retrieve relevant information to answer questions accurately. We introduce LLoCO, a technique that combines context compression, retrieval, and parameter-efficient finetuning using LoRA. Our approach extends the effective context window of a 4k token LLaMA2-7B model to handle up to 128k tokens. We evaluate our approach on several long-context question-answering datasets, demonstrating that LLoCO significantly outperforms in-context learning while using $30\times$ fewer tokens during inference. LLoCO achieves up to $7.62\times$ speed-up and substantially reduces the cost of long document question answering, making it a promising solution for efficient long context processing. Our code is publicly available at https://github.com/jeffreysijuntan/lloco.
Transferable and Principled Efficiency for Open-Vocabulary Segmentation
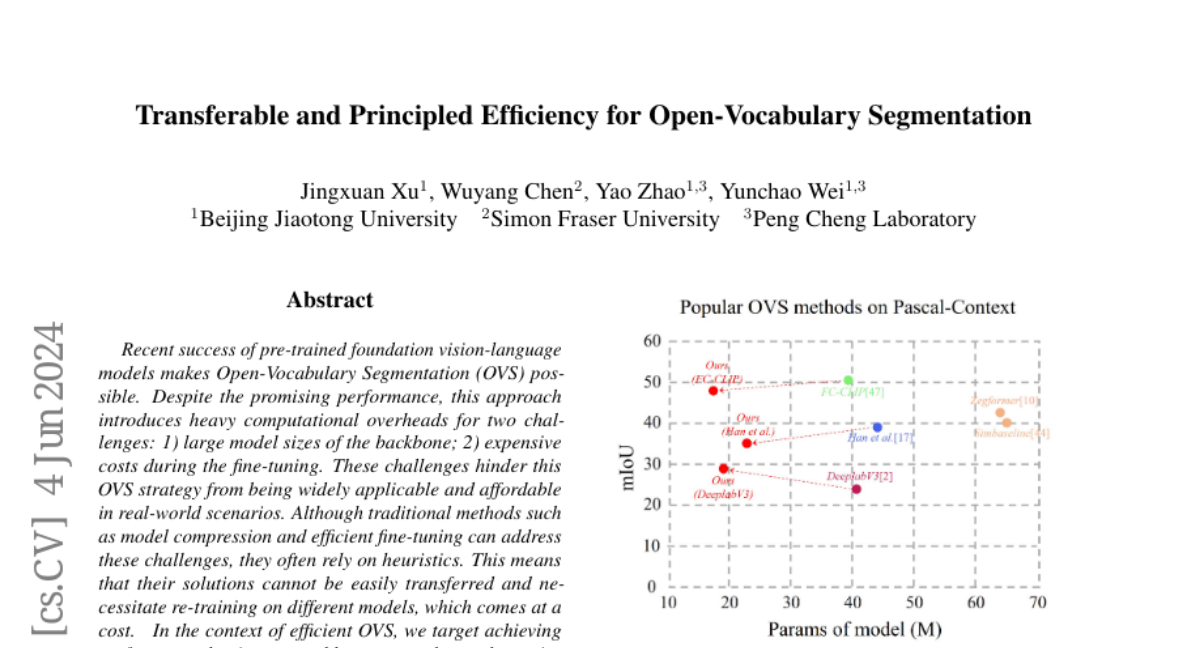
Recent success of pre-trained foundation vision-language models makes Open-Vocabulary Segmentation (OVS) possible. Despite the promising performance, this approach introduces heavy computational overheads for two challenges: 1) large model sizes of the backbone; 2) expensive costs during the fine-tuning. These challenges hinder this OVS strategy from being widely applicable and affordable in real-world scenarios. Although traditional methods such as model compression and efficient fine-tuning can address these challenges, they often rely on heuristics. This means that their solutions cannot be easily transferred and necessitate re-training on different models, which comes at a cost. In the context of efficient OVS, we target achieving performance that is comparable to or even better than prior OVS works based on large vision-language foundation models, by utilizing smaller models that incur lower training costs. The core strategy is to make our efficiency principled and thus seamlessly transferable from one OVS framework to others without further customization. Comprehensive experiments on diverse OVS benchmarks demonstrate our superior trade-off between segmentation accuracy and computation costs over previous works. Our code is available on https://github.com/Xujxyang/OpenTrans
Applying Guidance in a Limited Interval Improves Sample and Distribution Quality in Diffusion Models

Guidance is a crucial technique for extracting the best performance out of image-generating diffusion models. Traditionally, a constant guidance weight has been applied throughout the sampling chain of an image. We show that guidance is clearly harmful toward the beginning of the chain (high noise levels), largely unnecessary toward the end (low noise levels), and only beneficial in the middle. We thus restrict it to a specific range of noise levels, improving both the inference speed and result quality. This limited guidance interval improves the record FID in ImageNet-512 significantly, from 1.81 to 1.40. We show that it is quantitatively and qualitatively beneficial across different sampler parameters, network architectures, and datasets, including the large-scale setting of Stable Diffusion XL. We thus suggest exposing the guidance interval as a hyperparameter in all diffusion models that use guidance.
Sparse Laneformer

Lane detection is a fundamental task in autonomous driving, and has achieved great progress as deep learning emerges. Previous anchor-based methods often design dense anchors, which highly depend on the training dataset and remain fixed during inference. We analyze that dense anchors are not necessary for lane detection, and propose a transformer-based lane detection framework based on a sparse anchor mechanism. To this end, we generate sparse anchors with position-aware lane queries and angle queries instead of traditional explicit anchors. We adopt Horizontal Perceptual Attention (HPA) to aggregate the lane features along the horizontal direction, and adopt Lane-Angle Cross Attention (LACA) to perform interactions between lane queries and angle queries. We also propose Lane Perceptual Attention (LPA) based on deformable cross attention to further refine the lane predictions. Our method, named Sparse Laneformer, is easy-to-implement and end-to-end trainable. Extensive experiments demonstrate that Sparse Laneformer performs favorably against the state-of-the-art methods, e.g., surpassing Laneformer by 3.0% F1 score and O2SFormer by 0.7% F1 score with fewer MACs on CULane with the same ResNet-34 backbone.